I’ve been happy to see some recent articles about the OLPC that mention PenguinTV, although not by name. The BBC and AP both mention the existence of an RSS reader, and both understandably felt it necessary to describe what that means:
The machine comes with a web browser, word processor and RSS reader, for accessing the web feeds that so many sites now offer.
A wide range of programs can run on it, including a Web browser, a word processor and an RSS reader — the software that delivers blog updates to information junkies.
I have a feeling that people reading these descriptions will wonder why the heck 5th graders would care about RSS feeds. While these are decent enough descriptions of what RSS is traditionally used for, it misses the point of why I worked to bring RSS to the olpc. When I was envisioning how the children would use PenguinTV, this is what I saw:
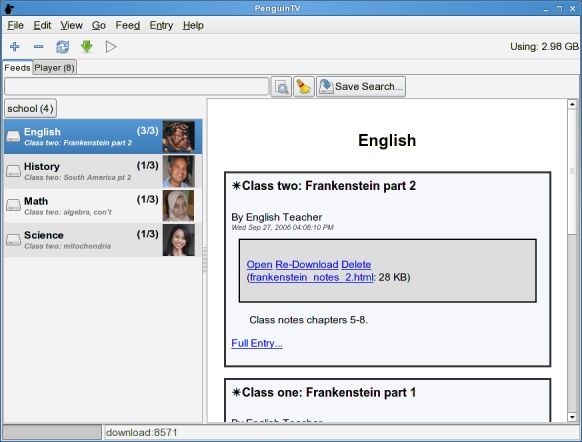
(Let me be clear here, this was my own personal hope and dream. It does not reflect the official position of olpc).
What’s important are not the specific images, subjects, and examples I’ve used, but how the data are presented. On the left is a list of subscribed feeds, representing classes the student is taking. On the right is a list of entries, of which there is one per class session. Each entry has associated notes and classroom materials. Every day this information would be automatically downloaded to the child’s laptop from the school server.
I think future students (if not current ones) will expect all classroom materials to be available online, whether from an internet server or a school server. I know I would have appreciated all my homework assignments as downloadable PDFs instead of crumplable, tearable, losable paper. Furthermore lectures for older kids could be recorded as audio or video and attached to the entry, meaning older students could catch up on missed classes. The storage of all these documents is managed directly by PenguinTV meaning that the student doesn’t need to know exactly where the files are stored on the hard drive.
So while RSS is known right now as a standard for “news junkies,” I hope that people can see how it can be used in other ways, including a classroom context.
With the introduction of The Journal, PenguinTV’s role has changed. The Journal will be a central part of the laptop experience and will keep track of all the user’s activities and files in an interface that may look similar to the screenshot above. This makes PenguinTV somewhat redundant for those uses. It still may have a role in retrieving data or as an offline web browser, but it’s probably not going to be the central class materials browser I envisioned.
Lately, it seems that my software has turned out to be a good testcase as a large software program with lots of dependencies. PenguinTV relies on Mozilla (to draw feeds), GStreamer (for audio and video playback), SQLite (for data storage), BitTorrent (for large files), and more. This makes it a great full-featured desktop program, but strains the laptop’s RAM capacity. (Right now most of the RAM is being used by mozilla, so improvements being made there are the most beneficial). Most of my work has been focused on improving PenguinTV so that it runs leaner and faster. If I can get it to perform well on the tiny laptop, not only will it be good for the children (should they become news junkies :)) but everyone running the desktop version as well.
I’m not at all disappointed to see the Journal doing what I imagined PenguinTV might do. After all, it must have been a good idea if someone else came up with it! The Journal is going to be one of the applications most often used by the children, so it needs to be much, much smaller than I could ever make PenguinTV. Because the Journal won’t be using html they won’t need mozilla, and they will probably use a more efficient storage mechanism than sqlite. Also PenguinTV does not work well with many entries in one feed, whereas the Journal will need to work for years-worth of data. So while it won’t be my own software, the kids will be getting the computer I wish had been available to me when I was in school. Lucky punks!